Keep your YAML Pipelines DRY
Introduction
I have previously mentioned Don't Repeat Yourself (DRY). That matters when writing good, maintainable code for applications - and also in DevOps pipelines when we build infrastructure automation targeting multiple environments.
It can be tempting to "just manually build" and defer automation until later, whether due to staffing or skills constraints, or just to get people working before infrastructure automation is implemented.
This often results in dissimilar environments where something works in one environment, but not another - not surprising when the environments are built manually and inconsistently.
One result is hacky processes and manual steps being implemented to "just get it working" in each environment, which is hard technical debt to pay off later (if ever).
Another result is duplication and repetition. "That pipeline plus these manual steps work for environment X, but always fail for environment Y. We don't have time to do it right, so let's just clone the entire pipeline and hack around until something work in Y."
Months later, you have a real mess on your hands. Maintenance burden is high, changes take much longer than they should, what works here does not work there, test suites do not have consistent baselines, and things break in production.
What can we do about this? This article shows a DRY approach to building pipelines which need to do largely the same tasks in multiple contexts or for multiple targets, without duplicating pipeline implementations or artifacts.
I use Azure DevOps (AzDO) pipelines targeting Azure infrastructure in this article, but the principles and approach apply equally to other platforms and systems. For example, you may need to run a software build, test, package and deploy process across multiple independent but similar contexts, ideally without duplicating pipelines.
Our Goals
What do we want to achieve?
We want pipelines and automation to target multiple contexts, such as infrastructure environments, with zero duplication of pipeline or automation artifacts (scripts, steps, etc.)
We want to be able to customize automation for environment-specific differences, such as deployment region(s), resource size or SKU, and so on with zero duplication
We want pipelines and automation to be modular and composable for maximum flexibility, reusability of generic steps across pipelines, and to contain the ripple effect radius of changes
We also have goals that are not specific to "zero duplication", such as managing pipelines in source control, adopting a granular "least privilege" security posture, and more. (See the sidebar "AzDO Classic Pipelines" at the end of this article for details.) Those are also valid goals, but outside the scope of this article.
Context
In this article, I'll show pipelines and artifacts deploying infrastructure to four target environments: Dev, Test, UAT, and Prod.
The requirement is that environments should be consistent with each other, such that eventual data and/or applications deployed into any of these environments "just work" without changes.
The environments should not differ from each other by, for example, using different compute, database, or other component technologies, but differences in size and other operational attributes must be supported.
Fully Duplicated Pipelines
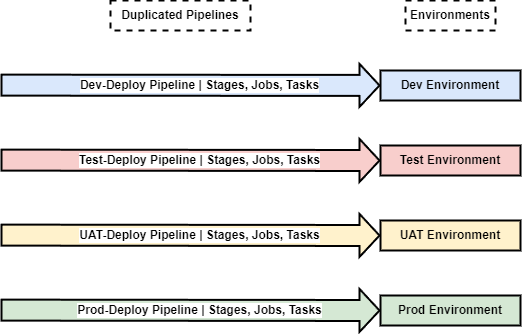
Let's say we have at least gotten past "everything is a one-off manual operation carried out in a UI tool". Often, the implementation goes something like "let's build a pipeline for our Dev environment", followed by effort, and it starts working.
This is followed by "let's not change anything in Dev", so the Dev pipeline is fully duplicated in turn for Test, UAT, and Prod, and then each of those duplicates is configured in place for its target environment.
The result? Four completely independent pipelines which start as perfect duplicates of each other, but will almost certainly "drift" over time, leading to the maintainability headaches I mentioned above.
Can you 100% guarantee that every single time one of these pipelines is changed, then the same change is replicated to every other pipeline? No? Then you are trading off (perceived) convenience now for pain later.
Modular, Composable Scaffold Pipelines and Generic Templates
Whew, that heading is a mouthful. What does it mean?
It means that for any pipeline work that is the same for each environment (e.g. "Deploy a Storage Account"), let's implement that work once, and re-use that work artifact across all our pipelines.
This way, when we need to change that work (e.g. our process to deploy a Storage Account needs a fix) we implement the change once, and all the pipelines immediately benefit.
We need to make such work units generic: the task to deploy a Storage Account, for example, should not have any attributes hard-coded into it. That means we don't hard-code the Azure region, the Storage Account SKU, or anything else, into the work unit that does the actual deployment!
So - how does that work unit know all those attributes? Simple - we inject the specifics into the pipeline environment at runtime. All such attributes can be persisted into a configuration store. Let's take all those hard-coded constants (SKU=S1, Size=Small, etc.) and remove them completely from our pipelines.
When a pipeline starts, it first loads the correct Configuration into the pipeline context. Configuration variables (keys and values) are exposed as environment variables in the pipeline context. Then our work units (such as the Storage Account deployment task) access the needed attribute data via those environment variables.
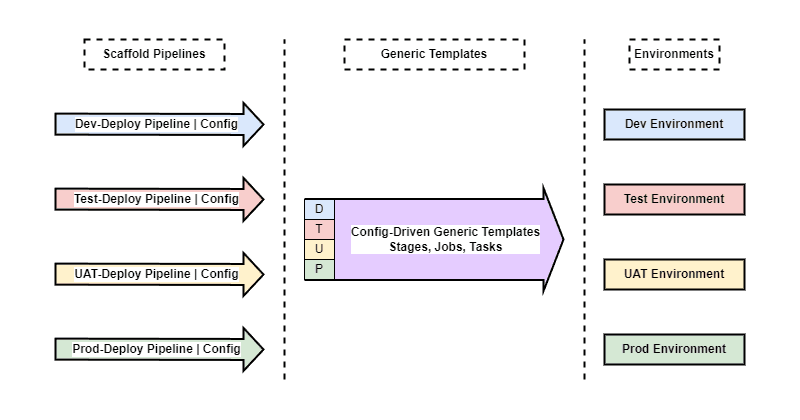
In this way, we minimize our environment specificity to the Scaffold Pipelines, which are simply minimal pipelines that are triggered and that load the correct configuration for the targeted environment, then inject that configuration into Generic Templates which do the actual work.
This is illustrated below: there is a Scaffold Pipeline for each environment (Dev, Test, UAT, Prod). The Scaffold merely loads the Configuration for that environment, then runs Generic Template work units.
The Generic Template (consisting of work units like Stages, Jobs, and Tasks) implements all functionality exactly once, and will target the correct environment based on the Configuration injected by the Scaffold Pipeline that was triggered.
Configuration Stores - Variable Groups
Where do we put all those configuration values? Into a configuration store. AzDO provides Variable Groups (VGs) and also supports Azure Key Vault (which can back an AzDO VG). I'll use AzDO VGs in this article.
You can find VGs in your AzDO project under Pipelines - Library. In the following screenshot, you can see that I have configured a VG for each environment - i.e. vg-dev, vg-test, vg-uat, and vg-prod - and that I also have vg-all and vg-security VGs.
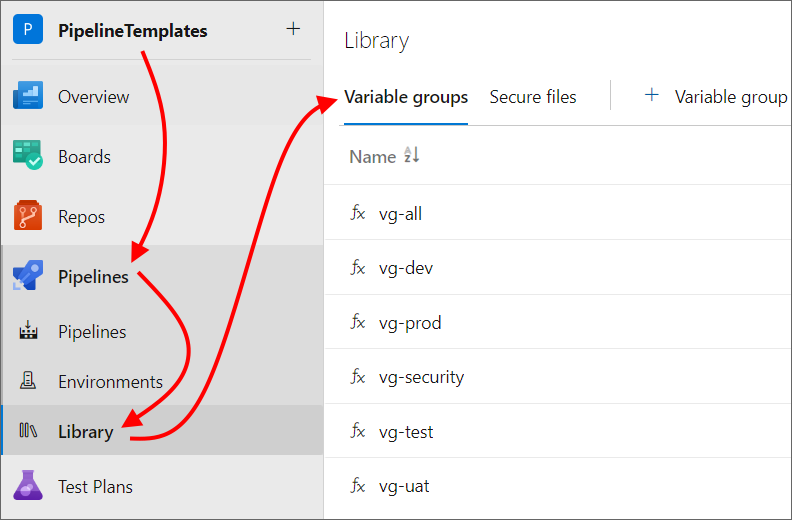
What's going on here? Several points to note -
Each environment has its own VG - hence
vg-devand so on.vg-allis there for values that are the same across all environments! (Remember how we want zero duplication? We don't even want to duplicate configuration values if they are the same anyway across all environments, such as your organization's name.)vg-securityis there so I can separate out certain values that are also the same across all environments, but that I may want to grant more restricted permissions to than forvg-all.How you create and name your VGs is entirely up to you - my VG names and separation are one way of doing it that works for me. The goal is to provide each environment what it needs, both what is environment-specific and what is the same across all environments.
So what does a VG actually look like? It's just a set of key-value pairs. Optionally, values can be stored as secret, such as for credentials or other sensitive information. The AzDO Command-Line Interface (CLI) can operate on VGs in scripted settings.
The screenshot below shows one of my environment-specific VGs listed above, vg-dev. Note the key/value pairs at the bottom. You can easily add more. In a real project, you would likely have many more variables than shown here in your VGs.
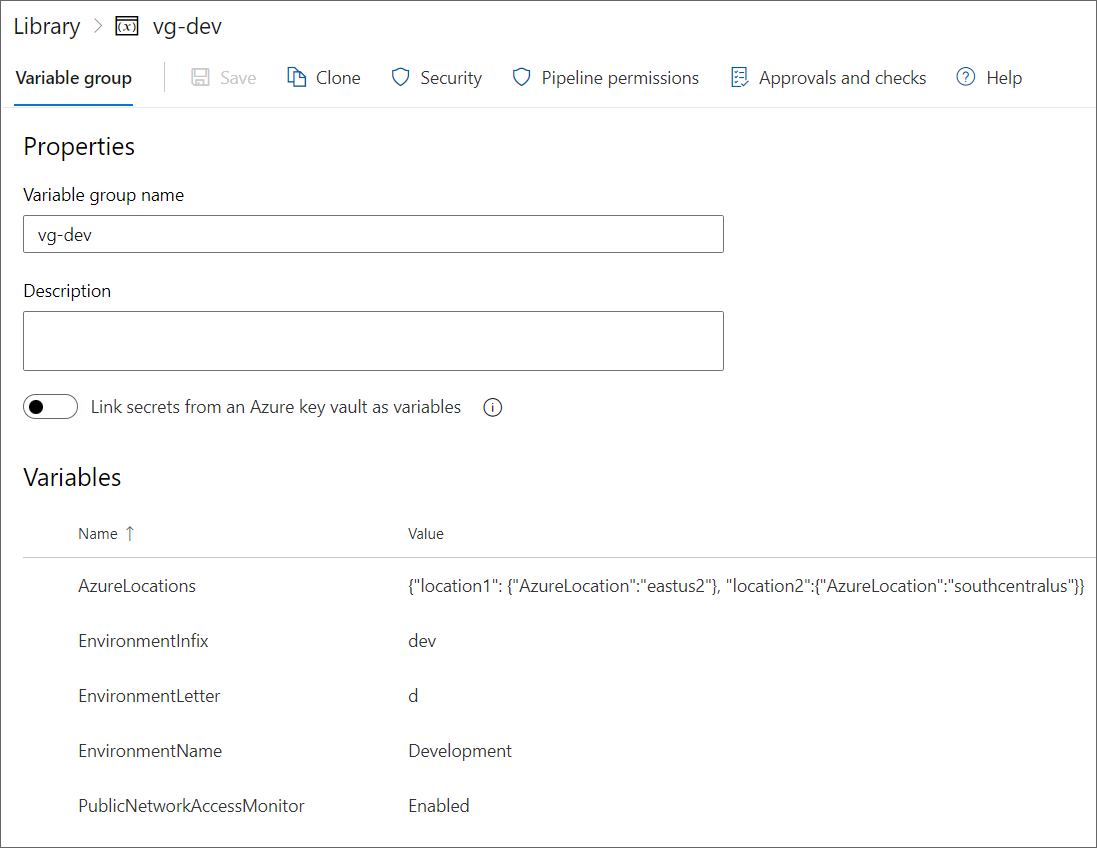
Note that the VG variable names are not environment-specific - only the values are! Why is this critical?
Because as our Generic Templates (stages, jobs, tasks) run, they will reference these values by name. It's important that whatever environment configuration is injected, the pipeline will always "find" the needed value in the injected configuration.
This is why you need to use the identical variable names across your environment-specific VGs. Whether you inject the configuration for Development (vg-dev), Test (vg-test), UAT (vg-uat), or Production (vg-prod) - your pipelines must always be able to get values for AzureLocations, EnvironmentName, etc.
If you instead named your variables like AzureLocations-dev, AzureLocations-test, and so on, it would be much more difficult to get your Generic Template artifacts running consistently. So be generic in your variable names, and only vary the values by environment. Thus, all my environment VGs use the same variable names.
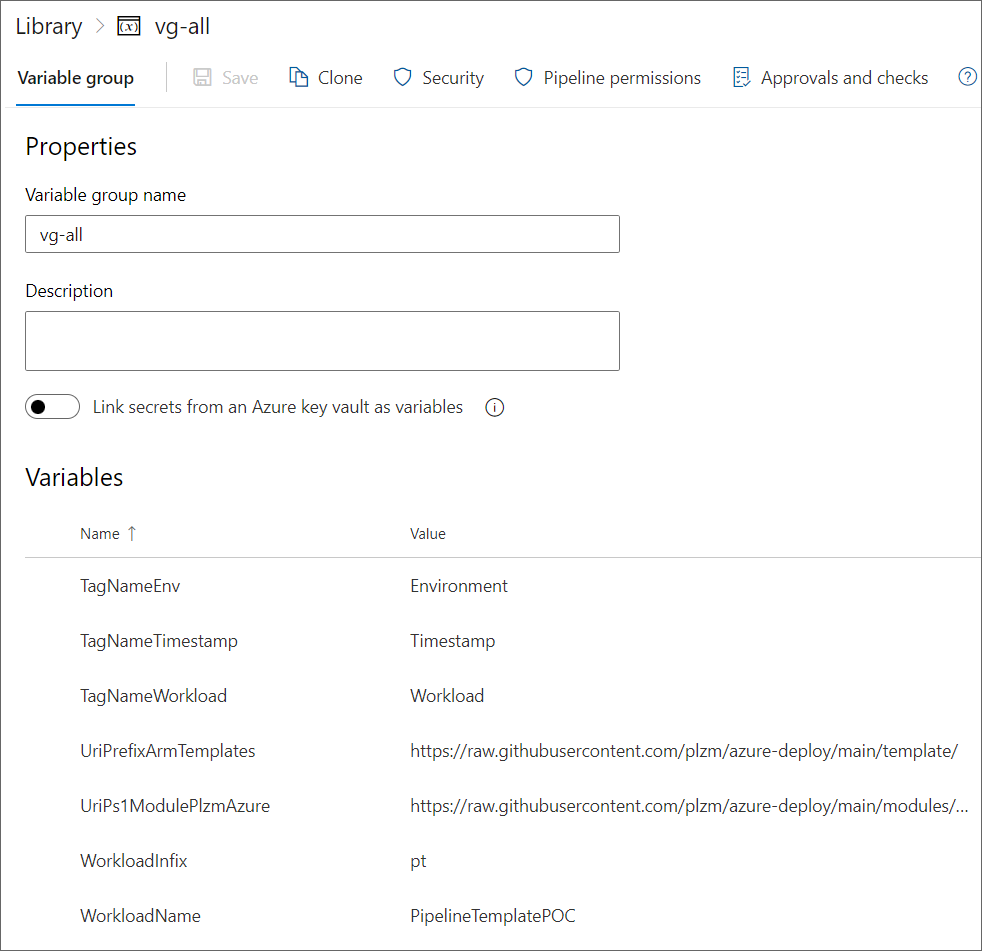
What does the vg-all VG look like? As you can see below, it contains variable keys/values that are invariant across environments - that is, these values are the same regardless of whether they are used in my Dev, Test, UAT, or Production environments. Therefore, why duplicate these in each of my environment VGs? You will have your own set of invariant keys/values, as applicable in your context.
Loading Configuration into a Scaffold Pipeline
Let's start putting it all together. Refer to the above diagram showing four Scaffold Pipelines, which are our starting points (these are the pipelines that get triggered and run all the Generic Template stages, jobs, and tasks).
Each Scaffold Pipeline loads Configuration. How does this work in practice? Let's look at two of these YAML pipelines, first Dev-Deploy. The YAML file is here:
https://github.com/plzm/azure-pipelines-poc/blob/main/.ado/pipelines/dev-deploy.yaml
This pipeline only has 19 lines:
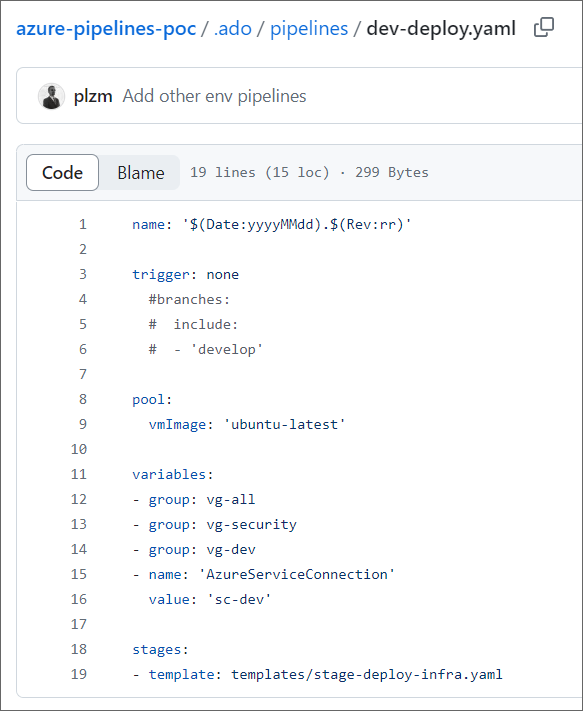
What is happening in this Dev-Deploy Scaffold Pipeline?
We provide a pipeline name and trigger(s). Note that I have it set to
trigger: none(manual trigger) for this article, but you can of course specify any of the supported automated triggers that make sense in your context.We specify pipeline compute - using the AzDO
pool:element.The
variables:element is where we import our Configuration! As you can see, I import three VGs:vg-all,vg-security, andvg-dev. I also specify which connection to Azure the pipeline should use, which is also environment-specific (sc-dev). This shows how I can both import Configuration that is the same for all pipelines and environments (vg-all,vg-security) as well as differentiate by environment (vg-dev,sc-dev).Lastly, I kick off the actual work by calling the Generic Template,
stage-deploy-infra.yaml.
The other Scaffold Pipelines are similar - they set the pipeline name and trigger(s), they specify Compute, they import Configuration, and then kick off the work using the same Generic Template! Here's the Test-Deploy Scaffold Pipeline - it only differs from Dev-Deploy on two lines (can you spot them and does the difference make sense to you)?
The YAML file is here: https://github.com/plzm/azure-pipelines-poc/blob/main/.ado/pipelines/test-deploy.yaml
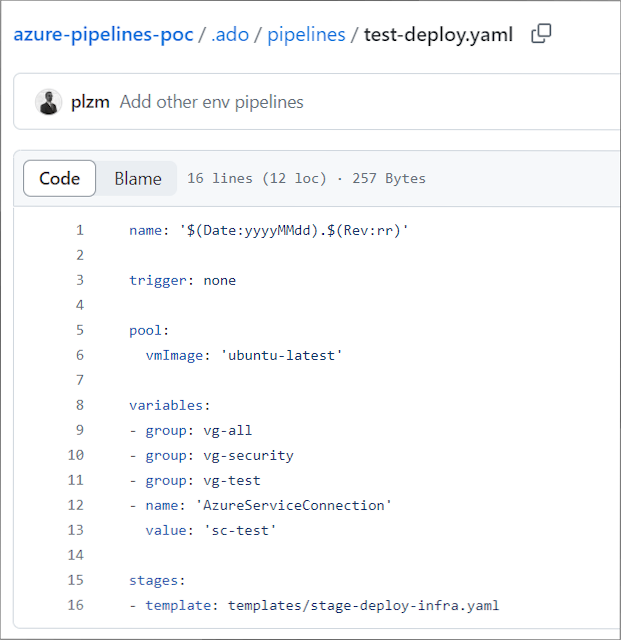
See how both Scaffold Pipeline files are almost identical, other than some comments and the two lines that differ by environment? And how both files conclude by launching the identical Generic Template, stage-deploy-infra.yaml?
This is the goal - minimize duplication with minimal differentiation (tiny Scaffold Pipelines) and maximal genericity (re-used Generic Templates that contain all the work to be done).
Generic Templates
So far, we've looked at the Configuration source (in this article, AzDO VGs) and the Scaffold Templates (the minimal YAML files above). Now let's look at the Generic Templates that actually do the work.
AzDO has full support for Templates, including parameterization. See the documentation for details: https://learn.microsoft.com/azure/devops/pipelines/process/templates
The Generic Templates are just... regular AzDO YAML files! With two important differences from standard AzDO YAML pipelines.
The template files do not contain full AzDO pipeline YAML structures. They only contain YAML for their work unit (i.e. stage, job, or task).
A YAML template file can contain its child work items directly - i.e. a stage file can also contain its job and task definitions in the same file - or it can call out to further template files that contain jobs and tasks.
So you could have your YAML hierarchy (stages, jobs, tasks) combined in one file, or split into individual stage, job, and task YAML files, or a combination of both - you will figure out the right mix in your context based on maintainability, and you can always change this over time.Template files should not hard-code anything that is environment-specific! Instead of hard-coded variable values, or hard-coded strings, or pipeline variables that are environment-specific... everything should be driven by the Configuration imported by the Scaffold Pipeline which was initially triggered.
Let's look into some of the Generic Template files in the GitHub repo for this article, https://github.com/plzm/azure-pipelines-poc.
You can see the /.ado/ folder with its /pipelines/ child folder that contains the Scaffold Pipelines, and in turn its /templates/ child folder that contains the actual template YAML files.
Note how /.ado/pipelines/ contains environment-specific files (dev-deploy.yaml, test-deploy.yaml, and so on), whereas /.ado/pipelines/templates/ contains no duplicated or environment-specific files.
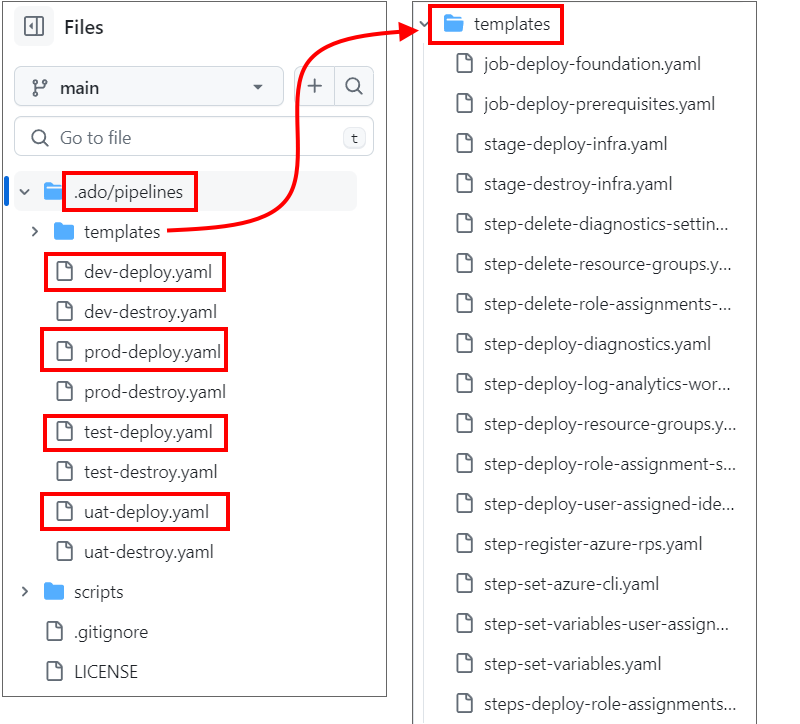
The Scaffold Pipelines all call stage-deploy-infra.yaml. Let's have a look into that file.
The file is at https://github.com/plzm/azure-pipelines-poc/blob/main/.ado/pipelines/templates/stage-deploy-infra.yaml
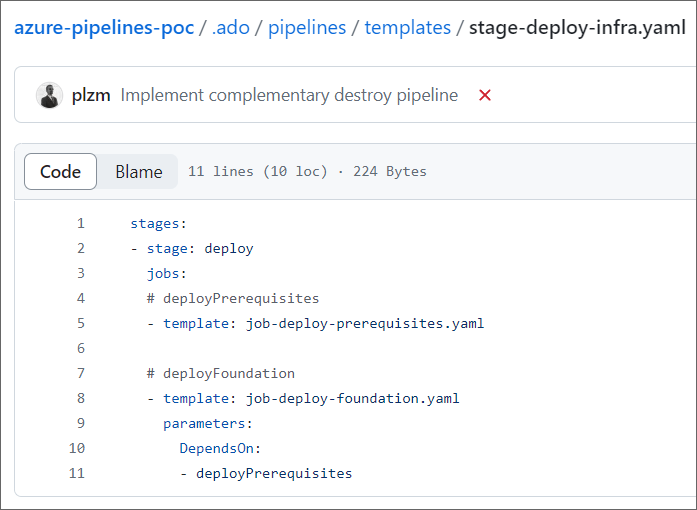
Note how this file is partial - it does not have all the extra YAML that the Scaffold Pipelines do, since it is a template.
Note also how this file, itself, calls templates for two jobs: job-deploy-prerequisites.yaml and job-deploy-foundation.yaml. This shows how we can compose our template hierarchy from individual files.
Let's look into the job-deploy-foundation.yaml file.
This file is at https://github.com/plzm/azure-pipelines-poc/blob/main/.ado/pipelines/templates/job-deploy-foundation.yaml.

In the job file above, you can see a mixture of steps: checkout: (to get the contents of the specified repositories), task: with direct inline work, and template: again to run individual steps, each in their own file for maximal reusability.
Let's drill in one more level and look into one of the step YAML template files run by the above job, step-deploy-log-analytics-workspace.yaml.
This file is at https://github.com/plzm/azure-pipelines-poc/blob/main/.ado/pipelines/templates/step-deploy-log-analytics-workspace.yaml.
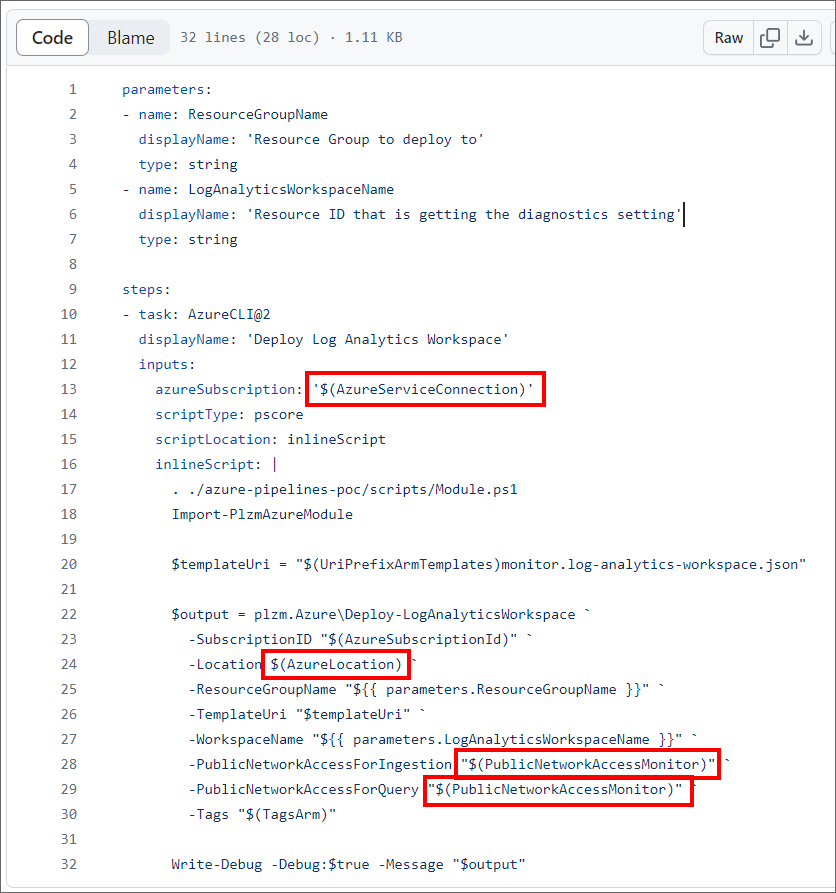
I have added several red rectangles in the above screenshot to emphasize those environment variables in the context of this article. Let's look at where each of these comes from.
$(AzureServiceConnection)is set right in the Scaffold Template! Each of those files (dev-deploy.yaml, etc.) sets this to the context- and environment-specific Azure connection to use. See the screenshot ofdev-deploy.yamlearlier in this article to see the YAML line setting this variable.$(PublicNetworkAccessMonitor)is set in thevg-devVG! This way, each context/environment (dev, test, uat, prod) can set its own value for this variable. Here, in dev, it is set to "Enabled" - but in other environments, we may want to set it to "Disabled". See the screenshot ofvg-devearlier in this article to see the value for$(PublicNetworkAccessMonitor)being set.$(AzureLocation)is set by using an additional, advanced AzDO capability - job matrix strategy - which I will discuss below in the context of this article.
Recap
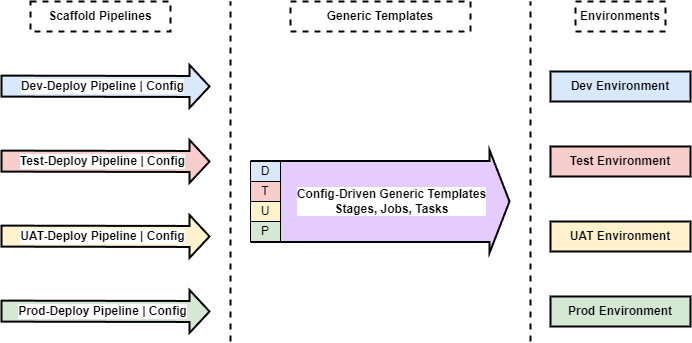
At this point, we have gone through Configuration stores (in this article, AzDO VGs), Scaffold Pipelines which are environment-specific and load Configuration, and Generic Templates which are run by the Scaffold Pipeline and driven by the injected Configuration.
This achieves our Goals (reference them near the top of the article)! Zero duplication, multiple targets, target-specific customization, and modularity and composability since we can re-use the job and step template files in other stage templates.
The following illustration shows the Configuration, Scaffold Pipeline, and Generic Template hierarchy and structure explored in detail above.
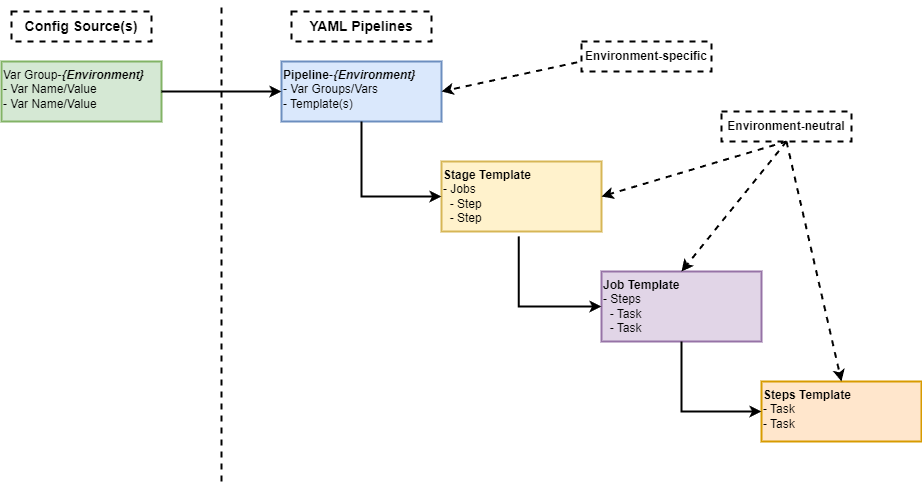
All the YAML files for this article are in the GitHub repo linked above, https://github.com/plzm/azure-pipelines-poc.
AzDO Job Matrix Strategy
What is a matrix strategy and why would we use one in this context?
The AzDO job matrix strategy lets you define a job once, with a set of inputs. A copy of the job will be run for each input in that set.
Let's make that real. What's an example?
In an infrastructure automation and deployment pipeline, we may want to deploy to a set of Azure regions, such as if we are building a high-availability system which continues running even if one of the Azure regions to which it was deployed becomes unavailable.
In Development, we may want to watch our costs and only deploy to one or two Azure regions. But in UAT or Production, we may want to deploy to more Azure regions, for greater scale and resilience.
If we follow a scale unit pattern (for example, as shown in Azure Mission-Critical), we will deploy the same infrastructure to each region we target.
Let's say we want to deploy to two Azure regions in Development, and to four Azure regions in Production. How can we do this in the context of this article, with zero duplication and without hacky workarounds?
Let's look again at the job template YAML file, job-deploy-foundation.yaml, specifically lines 6-7.

Here, we see that the matrix is provided a set of inputs $[ variables['AzureLocations'] ]. Where does this come from? It's set in the environment-specific VGs! Let's look at the difference between vg-dev and vg-prod.
In vg-dev, AzureLocations is set to include two Azure regions, location1 and location2:

The raw JSON is {"location1": {"AzureLocation":"eastus2"}, "location2":{"AzureLocation":"southcentralus"}}.
In vg-prod, AzureLocations is set to include four Azure regions, location1 through location4:

The raw JSON is {"location1": {"AzureLocation":"eastus2"}, "location2":{"AzureLocation":"southcentralus"}, "location3":{"AzureLocation":"northcentralus"}, "location4":{"AzureLocation":"westus2"}}.
Typically, as you will see in the AzDO documentation, a job's matrix strategy inputs are set statically, right in the YAML file.
In this context, instead of hard-coding matrix inputs in a YAML pipeline file (which would prevent the template from being generic), I use JSON sourced from a Configuration store to make this dynamic and reusable - which allows zero duplication of pipeline artifacts.
In summary: this is how we can vary the scale and geographic distribution of our deployment for each environment, using Configuration-driven AzDO job matrix strategies, and continue to use our zero-duplication, templatized pipeline approach!
Enough talk, let's deploy stuff
Finally: let's run our Scaffold Pipelines and see our deployment outputs in Azure.
First, I'll run the dev-deploy Scaffold Pipeline. Remember from above, this environment's Configuration specifies two target Azure regions in the job matrix strategy.
Indeed, the dev-deploy pipeline runs two copies of the deployFoundation job, one for location1 and one for location2, per the AzureLocations JSON shown above in vg-dev:
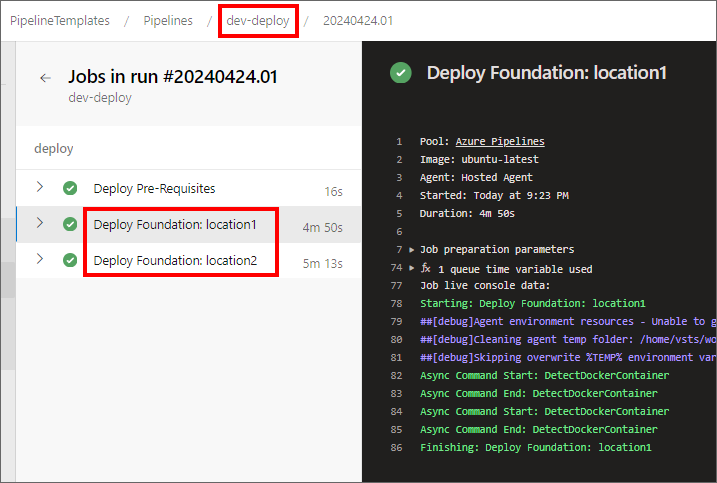
This results in corresponding deployments into those two Azure regions in our Development environment (denoted by -d- in the resource names):
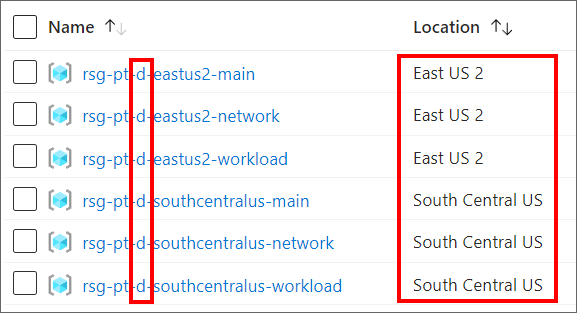
Now let's run the prod-deploy Scaffold Pipeline, which deploys into four Azure regions per the AzureLocations JSON shown above in vg-prod:
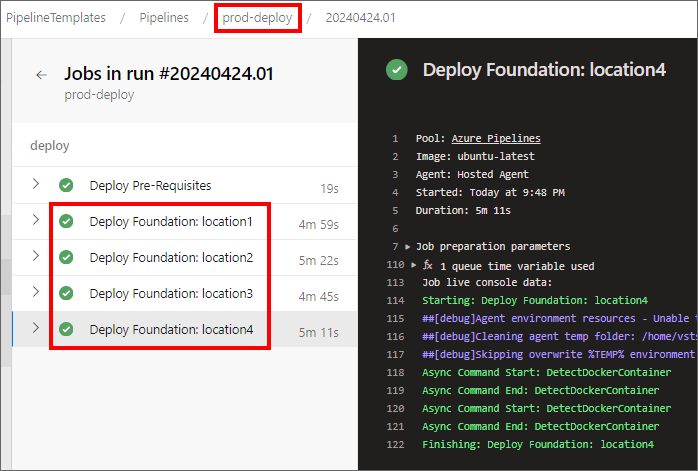
And this results in corresponding deployments into those four Azure regions in our Production environment (denoted by -p- in our resource names):
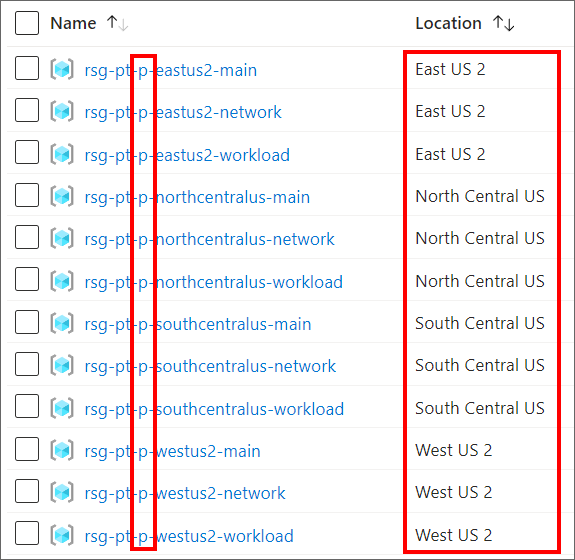
To wrap it all up: these deployment differences between environments were accomplished solely through differences in the Configuration which was injected from AzDO VGs by the Scaffold Pipelines.
Conclusion
In this article, I showed how to use Configuration and (very minimal) environment-specific Scaffold Pipelines in combination with config-driven Generic Templates to implement functionality that can target multiple environments with zero duplication, per-environment customization, and modular pipeline structure and hierarchy.
I hope this article is useful to you, and that it helps and inspires you to keep your YAML pipelines DRY! Check the GitHub repo https://github.com/plzm/azure-pipelines-poc for the YAML files.
Note: in the YAML pipelines I wrote for this article, I extensively use Azure infrastructure artifacts, such as a PowerShell module and a set of ARM templates, which I wrote and maintain in a separate GitHub repo,https://github.com/plzm/azure-deploy.
This article doesn't discuss those infrastructure artifacts because they are secondary to the Goals of this article, and because you can apply the principles discussed herein with any pipeline tasks targeting multiple contexts, not just infrastructure automation. But feel free to use my well-tested ARM and PowerShell artifacts in my azure-deploy repo for your Azure infrastructure work, or contact me for help if needed.
Sidebar: AzDO Classic Pipelines
AzDO supports two pipeline models: Classic and YAML. I strongly recommend avoiding Classic pipelines, and only using YAML pipelines. Why?
YAML pipelines are just files, and can be source-controlled and versioned like other file assets. Classic pipelines are UI, and while you can export them to YAML, that is manual and laborious.
YAML pipelines have a granular security model. You need to grant each YAML pipeline explicit access to the AzDO resources it uses, such as service connections, variable groups, and repositories.
This is consistent with a "least privilege" security posture, and reduces the risk of rogue pipelines accessing your important resources.
Classic pipelines do not support the granular security model: by default they can access everything.YAML pipelines - being file-based - are much easier to transition to another DevOps platform, if needed.
YAML pipelines enable the DRY approach described in the rest of this article. Classic pipelines unavoidably lead to duplication and redundancy.
See also this Microsoft dev blogs post, Disable creation of classic pipelines for additional justification for avoiding Classic pipelines, and how to disable their use entirely.
YAML Pipeline Granular Security Model
As noted above, AzDO YAML pipelines have a granular security model which requires you to grant each YAML pipeline access to each resource it uses (whereas Classic pipelines have access to everything by default).
You can grant these permissions when you create the pipeline, but if you do not, you will be prompted to do so at the pipeline's first run, as shown below.
Note that the pipeline will be blocked until you grant these permissions, so if your new pipeline seems to be taking a long time... go check whether it needs some permissions.
This screenshot shows the permissions I need to grant my Prod-Deploy pipeline, so it can access the needed resources.
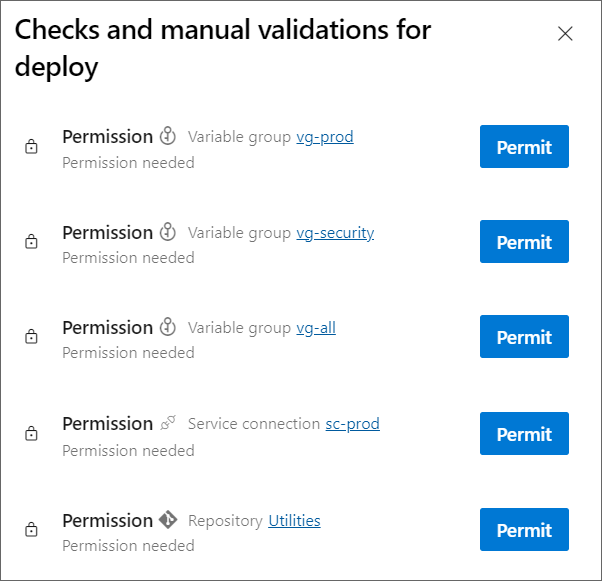
As I select each "Permit", I am asked to confirm.
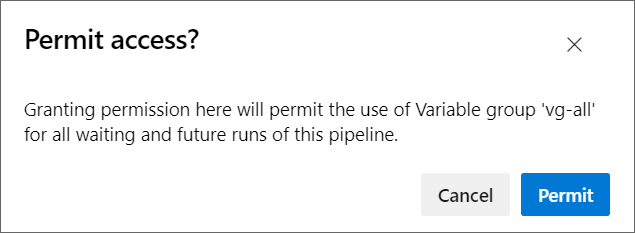
So not only do YAML pipelines allow us to achieve zero duplication and be modular and re-usable, they also allow for better DevOps platform security following a least-privilege model.
Happy DevOps-ing!