Azure VM Refresh with higher resiliency, less downtime, and lower risk
NOTE: I built a complete, end-to-end implementation (ARM templates, bash scripts, GitHub Actions CI/CD pipelines, additional technical detail) to accompany this post. You can find it at https://github.com/plzm/azure-vm-disk-swap/.
Gloomy Preamble
The longer a system lives, the greater the chances it will pick up something nasty. Spyware, bots, and ransomware are unfortunate realities, and almost all systems have multiple entry vectors for such "nastyware".
Compute corruption is a constant risk and survivability threat, and time is the enemy. The older a system, the higher the risk that it has been penetrated and corrupted.
This is especially critical for organizations that are attractive targets, or that have very high availability requirements (or both).
Brute-Force Approach
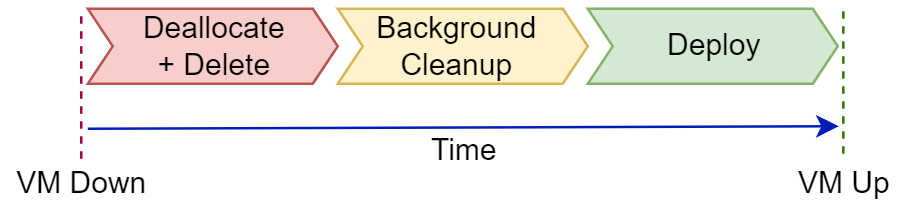
This is easy to mitigate, right? Just delete the whole compute (system, VM, cluster, etc.) and deploy new, clean replacement compute periodically.
Time-corruption risk mitigated, all done, blog post finished.
Downtime
Except it's not always that simple, especially in non-trivial production environments. In this post, I'll dig into Virtual Machines (VMs) but similar concepts apply to other compute.
In addition to deleting a VM and its components (e.g. disks, NICs, public IP addresses), there may be additional background cleanup tasks Azure Resource Manager (ARM) needs to do, such as removing the VM from Microsoft Defender for Cloud Just-in-Time (JIT) Access after the VM is deleted.
This will matter more if certain constraints apply, such as having taken a dependency on the VM resource name, which must be unique within the Resource Group.
You may not be able to deploy a new version of an Azure VM which must use the same resource name as the one you just deleted, until all delete and cleanup tasks have completed, including any background ARM tasks. This means your downtime may be longer! (Again, note that this particular constraint will not apply if you never re-use resource names.)
More generally, anytime you delete a resource first, and only afterward begin creating its replacement, you are taking a risk of added downtime in case anything at all during the replacement deployment does not work.
For example:
What if your Azure subscription or an Azure service you need has hit a limit, quota, or constraint? You will have to mitigate the limit, including possibly filing an Azure support ticket and waiting for support to help you resolve the issue, during which time your replacement deployment cannot complete.
What if the Azure region you are deploying into has a current deployment or availability issue, slowing or even preventing your replacement deployment from completing? (You can check for these at status.azure.com and in the Azure portal's Service Health blade)
Or what if your deployment process or workload simply had a defect slip in which affects availability after deployment?
Best Practices vs. Real World
Generally, it's a best practice to have the replacement resource deployed and available before stopping, deallocating, and/or deleting an end-of-life resource.
You swap the replacement resource in to take over the old resource's workload, and you wait and test to make sure the replacement resource is running and the old resource has been "drained". How to do this will vary by workload and resource, but it's a well-established pattern and approach to minimize or eliminate downtime when updating resources.
However, as mentioned above, sometimes we have constraints which prevent us from using this approach. I have been involved in real-world projects with production Azure deployments where this was true. Not every workload has been modernized to an approach like Azure Mission-Critical yet.
This blog post, then, is about how to proceed for minimal downtime and maximal resiliency (recoverability) under constrained conditions.
Constraints
I have seen all these constraints in real-world projects and deployments:
Dependency on Azure resource names - replacement resources must be deployed with the same Azure resource name as the resource being replaced
Highly secure environment - Azure VM agents and most extensions (including custom script extension) not allowed, but post-deployment VM configuration/installation required
- See my previous post Using transient SSH keys on GitHub Actions Runners for Azure VM deployment and configuration for a no-agent, no-extension approach to solve this issue
Least trust required - CI/CD environments to store only Azure control plane access credential (a Service Principal client ID and key), no other credentials or keys
Additionally, deployment artifacts (e.g. scripts) must be testable in local development environments and also runnable from CI/CD pipelines with minimal to zero duplication (e.g. setting environment variables one way locally, and a different way in a CI/CD context) of data or approach.
This one is more about DevOps productivity but there is a code-entropy and security leak concern here too; twice the maintenance burden (to maintain local dev/test as well as CI/CD config and environment setup) means twice the chance to miss and inadvertently disclose something.
See my previous post Don't Repeat Yourself: Environment Variables in GitHub Actions and locally for my approach to eliminate duplication and still configure a local dev environment as well as a CI/CD runner as needed. Remember: Don't Repeat Yourself.
Level-Set
So where are we? We need to
Periodically replace resources to mitigate corruption and entropy risks
Minimize downtime during replacement
Minimize risk of disrupted replacement deployment
Maximize resiliency - if replacement deployment fails, we need a fast rollback to the previous, known-working resource
The brute-force approach of first destroy the old resource, then cross fingers and hope the replacement deployment works perfectly, rapidly, and the first time... is too risky and not good enough in a production or otherwise important environment.
So what is an Azure VM?
When we think of a VM, we typically think of it like a physical machine. It's a unit of compute that has components like CPU, RAM, disk, network, and so on.
This viewpoint leads naturally to a "destroy it all" brute-force approach. However, let's take a closer look at an Azure VM.
An Azure VM is an ARM Resource Type: Microsoft.Compute/virtualMachines.
But it does not "bundle" (include) the components we would typically consider parts of a VM, like network interfaces, public IP addresses, and disks! Those have their own ARM Resource Types:
And... these various resources, all of which together constitute our notion of a "VM", are separately deployed in Azure.
State
The VM's OS and applications are installed and maintained on the disk. This is where the VM's state is preserved (along with hypervisor RAM allocated to the VM while the VM is running).
The VM, Network Interface and Public IP address resources do not maintain any user state. They do not change as the OS and applications on the disk change. In fact, thanks to Azure's resource model, we can actually dissociate resources like these from the VM resource, associate them to another VM resource, and continue using them there!
So why would we delete stateless resources like the VM, Network Interface, or Public IP Address in order to update the OS? Because it's a bit easier to just "delete all", or perhaps because we haven't thought about stateful vs. stateless and seen that we just need to refresh where state is held.
Would you throw away your nice gaming rig because your OS needed to be updated? Of course not. You'd keep the rig, and its high-end graphics card and network interface card, and you'd just re-image or replace the OS disk. Let's take the same careful approach here.
Advantages of a non-destructive approach
If we just replace the disk and keep the VM, Network Interface, and Public IP address resources "as is", we get several advantages from such a non-destructive approach.
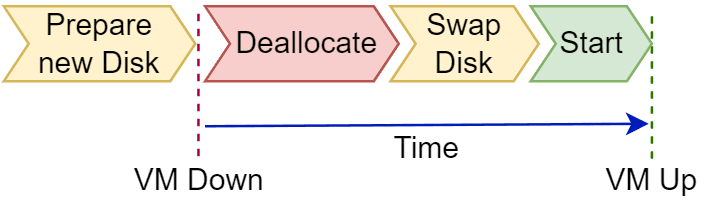
We can prepare the new disk ahead of time, then swap it in and check if everything works. If not, we can rapidly swap back to the previous, known-good disk with minimal downtime (since we don't have to re-deploy all the other components). This gives us minimal downtime as well as an immediate rollback path for higher resiliency.
We can even prepare multiple disks and easily swap in the correct one for scenarios like same-baseline testing, or multi-OS testing, etc.
Since we're preserving the stateless resources (VM, NIC, PIP, etc.), existing platform dependencies can also be preserved and no delays are incurred for policy assignments, just-in-time access, privileged identity, managed identity and other dependency cleanups from the deleted resources, and re-creations for the replacement resources.
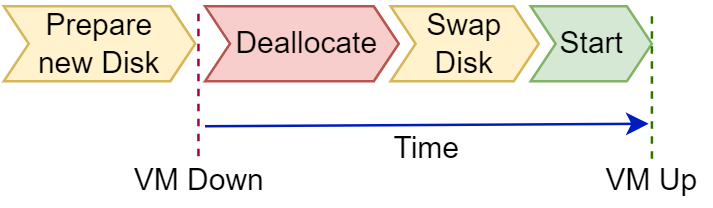
Scale and Automation
Creating a new OS disk for an Azure VM is inherently simple. The Azure Marketplace has lots of OS images available, and a new VM can easily be rolled out with a disk built from one of these images.
However:
What if we need OS disks based on custom images, which include our own custom configurations and installations, and perhaps use OS versions that are not available in the Azure Marketplace?
What if we need to operate in a least-privilege context?
What if we are in a restricted environment where we cannot have the Azure Linux Agent or various VM extensions on our VMs?
What if we need to create and swap disks for many VMs on a recurring basis?
What if we need to automate disk creation and swapping completely, while maintaining rollback?
In the GitHub Repo linked at the top of this post, I built a complete, end-to-end implementation which achieves all of the above criteria. Below, I'll highlight key parts of the implementation, but see the repo for deeper technical detail and to review all the scripts, templates, and pipelines.
Custom OS Disk Images
We can create and store our own custom disk images so they can be used to create Azure VM OS disks which include our custom configurations and installations.
The process is scripted out in detail in the GitHub repo, but here are the key points.
We will deploy and use an Azure Compute Gallery to store and share our custom OS disk Image Definitions and Images.
We will create an Image Definition for each type of image that we will manage ongoing. An Image Definition is metadata that defines the specific OS and version and various system requirements.
We will create an Image Version, associated to an Image Definition. The Image Version is the versioned artifact from which OS disks can be created. We can create progressively newer or different Image Versions based on the same Image Definition.
If we use multiple OSes in our VMs, we would have an Image Definition for each OS. We would create these Image Definitions once, and use them until they are no longer needed (e.g. we stop using a particular OS or version for which we had created an Image Definition).
If we adopt a monthly frequency for refreshing our Azure VMs with new images, we would create a new Image Version each month for each Image Definition. We would then create new OS disks off these new Image Versions each month.
The GitHub repo contains the following artifacts:
What's this about a source VM? We have to build a VM from which we will get our new Image Version.
The implementation I built deploys a VM based on an Azure Marketplace image, performs custom configuration and installation steps on the VM, then generalizes the VM, captures an Image Version from it, and stores the new Image Version in the Azure Compute Gallery.
This Image Version will then be used to create new VM OS disks. VMs that boot off these OS disks will already have the required configurations and installations! See the linked script above for implementation details.
In addition to the scripts linked above, the GitHub repo also contains two GitHub Actions workflows which include deployment of the Azure Compute Gallery, creation of the Image Definition, deployment and capture of a source VM, and creation of an Image Version from the source VM.
01 Deploy Infra deploys foundational infrastructure used for the implementation, including the Azure Compute Gallery.
03 Create Source Image creates the Image Definition, Source VM, and Image Version as well as running VM generalize and capture steps.
Least Privilege and Constraints on Azure Linux Agent or VM Extensions
CI/CD pipelines which deploy Azure resources need an authentication context within which to deploy.
At the Azure control plane - i.e. to deploy Azure resources - this typically requires the CI/CD environment to have a Service Principal name and secret, with the Service Principal being in the required Role-Based Access Control (RBAC) roles.
In an environment where we may not have the Azure Linux Agent or various Azure VM extensions like the Custom Script extension available on Azure VMs, we also need data plane access to access a source VM and perform our required configurations and installations.
See my previous blog post Using transient SSH keys on GitHub Actions Runners for Azure VM deployment and configuration for details on configuring Azure authentication for GitHub Actions runners as well as my approach for one-time-use-only SSH keys for immediate post-deployment configuration of source VMs.
This enables us to use GitHub Actions pipelines for VM deployment, configuration and capture without needing to store any durable data plane (VM OS) access credentials in a GitHub repository. Naturally, this approach can also be used in other CI/CD systems.
Let's do this for many VMs
In a scheduled (e.g. every month) VM OS disk swap, we will want to automate Image Version creation and OS disk swap across many VMs. So we have to solve for "Which VMs should have new OS disks created and swapped on?"
We want to avoid name hard-coding or brittle processes, and we don't want to impose arbitrary naming rules on our app and ops teams. We also don't want to modify our GitHub Actions workflows every time we need to generate new Image Versions and OS disks. So how can we make it as easy as possible to flexibly designate which VMs are in scope?
Azure Tags are applied to Azure resources to enable many scenarios, including querying Azure for a list of all Azure resources which have a specific tag name and value.
VMs that are in scope for recurring OS disk refresh can be tagged with a standard tag name, and a value that indicates whether the VM should be refreshed. I chose to use a tag named AutoRefresh and a value of true to indicate that a VM is a candidate for periodic OS disk generation and swapping.

Then, when it's time to run a process to create a new OS disk for each VM in our Azure environment which has AutoRefresh=true, we can use an Azure Resource Graph query to retrieve all VMs which have this tag name and value.
az graph query -q 'Resources | where type =~ "microsoft.compute/virtualmachines" and tags.AutoRefresh =~ "true"'
I use a modified version of the above Azure Resource Graph query to first select VMs with this tag name and value, then to project only the properties I need for further processing, since the above query returns a lot of JSON.
vms="$(az graph query -q 'Resources | where type =~ "microsoft.compute/virtualmachines" and tags.AutoRefresh =~ "true" | project id, name, location, resourceGroup' --subscription ""$SUBSCRIPTION_ID"" --query 'data[].{id:id, name:name, location:location, resourceGroup:resourceGroup}')"
Then I iterate through all the returned VMs and create a new OS disk for each, based on an Image Version.
while read -r id name location resourceGroup; do
diskName="$name""-""$VM_SUFFIX_VNEXT"
echo "Create OS disk ""$diskName"" for VM ""$location""\\""$resourceGroup""\\""$name"
az disk create --subscription "$SUBSCRIPTION_ID" -g "$resourceGroup" -l "$location" --verbose \
-n "$diskName" --gallery-image-reference "$galleryImageRefVNext" \
--os-type "$VM_OS_TYPE" --sku "$OS_DISK_STORAGE_TYPE"
done< <(echo "${vms}" | jq -r '.[] | "\(.id) \(.name) \(.location) \(.resourceGroup)"')
NOTE: see the GitHub repo's README for details on environment variable management. All the variables in all-upper-case are environment variables.
The GitHub repo contains the complete script that does this.
There is also a GitHub Actions workflow which includes this step: 04 Create OS Disks from Image.
NOTE: we can require that a specific tag is applied to Resources by using Azure Policy. There are many built-in policies available to enforce tag usage. My script above that queries for VMs with a specified tag name and value will work whether or not resources have the tag; if a resource does not have the tag, it won't match the query predicate. But you may need to be more prescriptive about enforcing a tag's presence.
Rollback - and OS Disk Tagging
One of our goals stated above was to maintain a rollback path. Let's say we create a new OS disk for a critical VM, swap the new OS disk onto the VM, start the VM, and the VM experiences errors or failures. We want to rollback to the previous OS disk.
The implementation I built does not delete previous OS disks after they are swapped for newer ones. (The GitHub Actions workflow that periodically creates new OS disks would be a great place to add a rolling-x-months-back delete step.)
So how do we rollback a VM to its previous OS disk?
There are several ways. The easiest is built right into the Azure portal! We can display the VM which has errors or failures in the portal, find the disks blade, and use the "Swap OS disk" feature. Since we didn't delete the previous OS disk, it's still available for swapping back to!
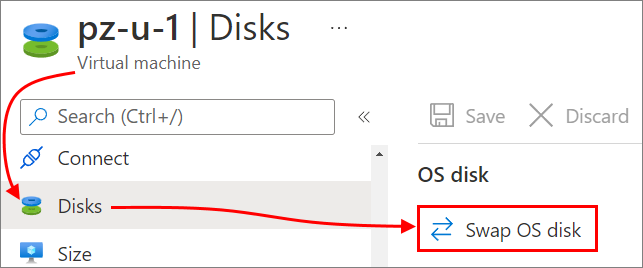
However! While this works on an occasional basis, Azure portal use is manual and not suitable at scale or for automation. What's a better way?
I implemented a more general approach for use at scale across many VMs, again using tags. This time, I used an OsDiskName tag to store a value corresponding to the name of the disk resource that should be the OS disk on the VM.
Recall that in the previous section above, I used an Azure Resource Graph query to find VMs for which a new OS disk needed to be created, and then did the OS disk creation. The above process did not actually do the OS disk swap. A separate process - discussed in this section - does the OS disk swap.
Why separate OS disk creation and swapping? Because we may want to create new OS disks once in a time period (e.g. each month), but we may need to swap OS disks many times, whether to rollback after a failure and then roll forward again, or to swap OS disks back and forth for tests, etc. We want to be able to do OS disk swaps quickly without constantly recreating the OS disks if there is no need to do that.
I created another Azure Resource Graph query which again retrieves all VMs with AutoRefresh=true, but this time projects additional fields I'll use to determine if a VM needs its OS disk swapped. (Above, I determined if a VM needs a new OS disk created.)
vms="$(az graph query -q 'Resources | where type =~ "microsoft.compute/virtualmachines" and tags.AutoRefresh =~ "true" | project id, name, location, resourceGroup, currentOsDiskName=properties.storageProfile.osDisk.name, newOsDiskName=tags.OsDiskName' --subscription ""$SUBSCRIPTION_ID"" --query 'data[].{id:id, name:name, location:location, resourceGroup:resourceGroup, currentOsDiskName:currentOsDiskName, newOsDiskName:newOsDiskName}')"
while read -r id name location resourceGroup currentOsDiskName newOsDiskName
do
if [[ -z $newOsDiskName ]]
then
echo "$location""/""$resourceGroup""/""$name"": OsDiskName tag is not set or value is empty. No change will be made to VM."
elif [[ "$newOsDiskName" == "$currentOsDiskName" ]]
then
echo "$location""/""$resourceGroup""/""$name"": OS disk does NOT need to be changed. No change will be made to VM."
else
echo "$location""/""$resourceGroup""/""$name"": OS disk needs to be changed."
# etc. - see script in GitHub repo for implementation details
done< <(echo "${vms}" | jq -r '.[] | "\(.id) \(.name) \(.location) \(.resourceGroup) \(.currentOsDiskName) \(.newOsDiskName)"')
As you see in the above script fragment, as I iterate through the list of VMs returned by my Azure Resource Graph query, I check whether each VM even needs its OS disk to be swapped by checking the value of the OsDiskName tag.
If the OsDiskName tag is not present on the VM, or if its value matches the name of the current OS disk on the VM, then no change is needed to the VM.
But if the OsDiskName tag is present, and its value differs from the name of the VM's current OS disk, then I know a change is needed.
But wait! What if the OsDiskName tag contains a nonsense value that doesn't correspond to an available disk? No problem - the script also checks whether the disk actually exists before swapping it onto the VM, by running an az disk show command which will return null if the disk does not exist.
newOsDiskId=$(echo "$(az disk show --subscription $SUBSCRIPTION_ID -g ""$resourceGroup"" -n ""$newOsDiskName"" -o tsv --query "id")" | sed "s/\r//")
if [[ ! -z $newOsDiskId ]]
then
echo "Disk referenced by tag value exists. Starting swap onto VM."
echo "Deallocate VM"
az vm deallocate --subscription "$SUBSCRIPTION_ID" -g "$resourceGroup" --name "$name" --verbose
echo "Update the VM with new OS disk ID"
# SPECIFY THE CORRECT OS DISK ID TO SWAP -->TO<-- WITH THE --os-disk PARAMETER
az vm update --subscription "$SUBSCRIPTION_ID" -g "$resourceGroup" --verbose \
-n "$name" --os-disk "$newOsDiskId"
echo "Start VM"
az vm start --subscription "$SUBSCRIPTION_ID" -g "$resourceGroup" -n "$name" --verbose
fi
The GitHub repo contains the complete script that iterates through VMs and swaps their OS disks to the disk indicated in the OsDiskName tag.
There is also a GitHub Actions workflow which includes this step: 06 Swap OS Disks.
But how do we update the OsDiskName tag for many VMs, e.g. on a scheduled basis? We may want to tag each VM with AutoRefresh=true with a new OS disk name each month, so that another process can run and ensure each VM's attached OS Disk corresponds to the value in the OsDiskName tag.
We'll run an Azure Resource Graph query for Azure VMs with AutoRefresh=true, and we'll refine this query by adding a predicate for VMs whose OsDiskName tag does not match the "next" OS disk name we'll generate. (This predicate is in case we've already upgraded some VMs to the "next" OS disk; we don't want to operate on them again.)
Then we'll just update the OsDiskName tag on each VM with the correct "next" value.
query="Resources | where type =~ \"microsoft.compute/virtualmachines\" and tags['AutoRefresh'] =~ \"true\" and not(tags['OsDiskName'] endswith_cs \"""$VM_SUFFIX_VNEXT""\") | project id, name"
vms="$(az graph query -q "$query" --subscription "$SUBSCRIPTION_ID" --query 'data[].{id:id, name:name}')"
while read -r id name location resourceGroup
do
tagValue="$name""-""$VM_SUFFIX_VNEXT"
echo "Update VM ""$id"" OsDiskName tag to ""$tagValue"
az tag update --subscription "$SUBSCRIPTION_ID" --resource-id "$id" --operation Merge --tags OsDiskName="$tagValue"
done< <(echo "${vms}" | jq -r '.[] | "\(.id) \(.name)"')
GitHub Actions Workflows
The GitHub repo plzm/azure-vm-disk-swap contains the full end-to-end implementation of everything above, including GitHub Actions workflows which execute all the described steps.
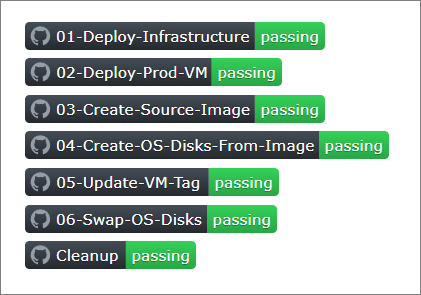
The Workflows do not all need to be run together.
01 Deploy Infrastructure can be run as needed. You do not need this workflow if you have your own Azure infrastructure corresponding to the resources deployed in this workflow, especially the Azure Compute Gallery.
02 Deploy Prod VM simply deploys a "production" VM which I use to swap OS disks later. There is nothing special about this VM. You can use any VM you have as long as it has the required tags (see repo README) and matches the OS publisher, SKU and version specified in the environment variables.
03 Create Source Image can be run anytime to create a new Azure Compute Gallery Image Version from a source VM. This workflow deletes the source VM and associated resources at the end of the capture process. This is the first of the workflows you could set to run on a schedule, e.g. at the end of each month to create a new Compute Gallery Image Version from which to create new VM OS disks.
04 Create OS Disks From Image iterates through all matching VMs (tag
AutoRefresh=true) and creates a new OS disk for each VM, deploying it into the same Resource Group as the VM. Remember - this workflow only creates the OS disks, it does not do the actual swap (see discussion above).05 Update VM Tag can be run periodically to update the
OsDiskNametag on each matching VM to the "next" OS disk name. It should be run on the same schedule as the "04 Create OS Disks From Image" workflow.06 Swap OS Disks iterates through all matching VMs (
AutoRefresh=trueandOsDiskNametag does not match current VM OS disk name, and OS disk designated in theOsDiskNametag exists) and performs the OS disk swap. This can be run both on a schedule - e.g. after "04 Create OS Disks From Image" and "05 Update VM Tag" to finish an automated, recurring create/tag/swap cycle - as well as needed, e.g. after updating a VM'sOsDiskNametag to denote that a different OS disk should be swapped onto the VM. Recall that the process will ignore VMs where theOsDiskNametag matches the current OS disk name, so this process will only operate on the appropriate subset of all VMs.
OS Disk Swap in a GHA Workflow run
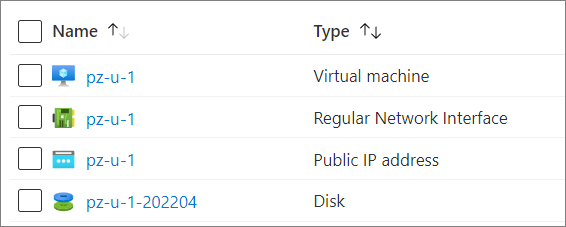
How would an OS disk swap look in a real GitHub Actions workflow run? I'll use a deployed VM which has an OS disk named pz-u-1-202204. This OS disk was generated for April 2022, as its name implies.

I have already created a new OS disk for this VM. The new OS disk is in the same Resource Group. It's named for May 2022, as I have decided on a monthly refresh schedule.
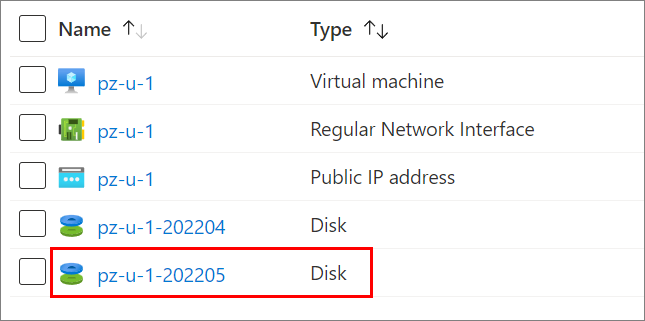
Since the new OS disk exists and is ready to be swapped onto the VM, I update the OsDiskName tag on the VM to reflect the new OS disk name.

Now I can run the 06 Swap OS Disks GitHub Actions workflow and the workflow correctly detects that the VM needs its OS disk swapped, and performs the swap.
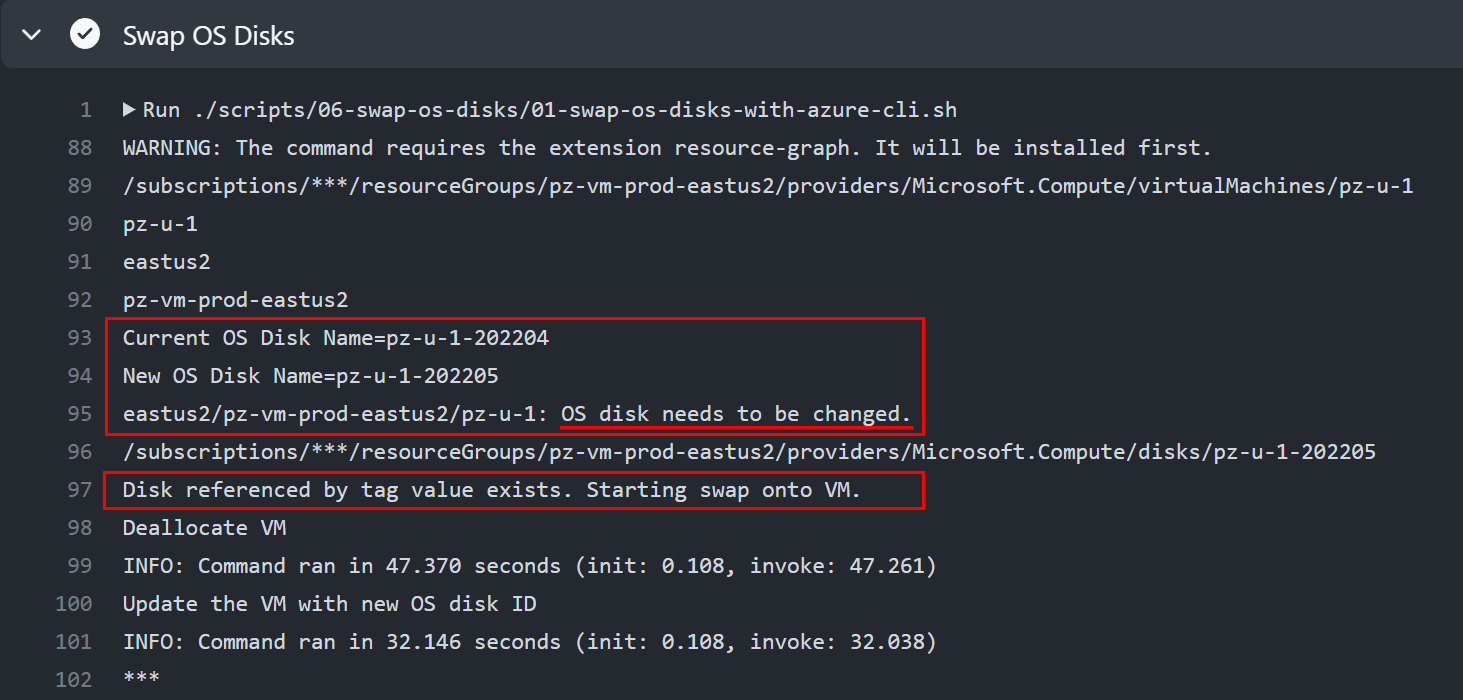
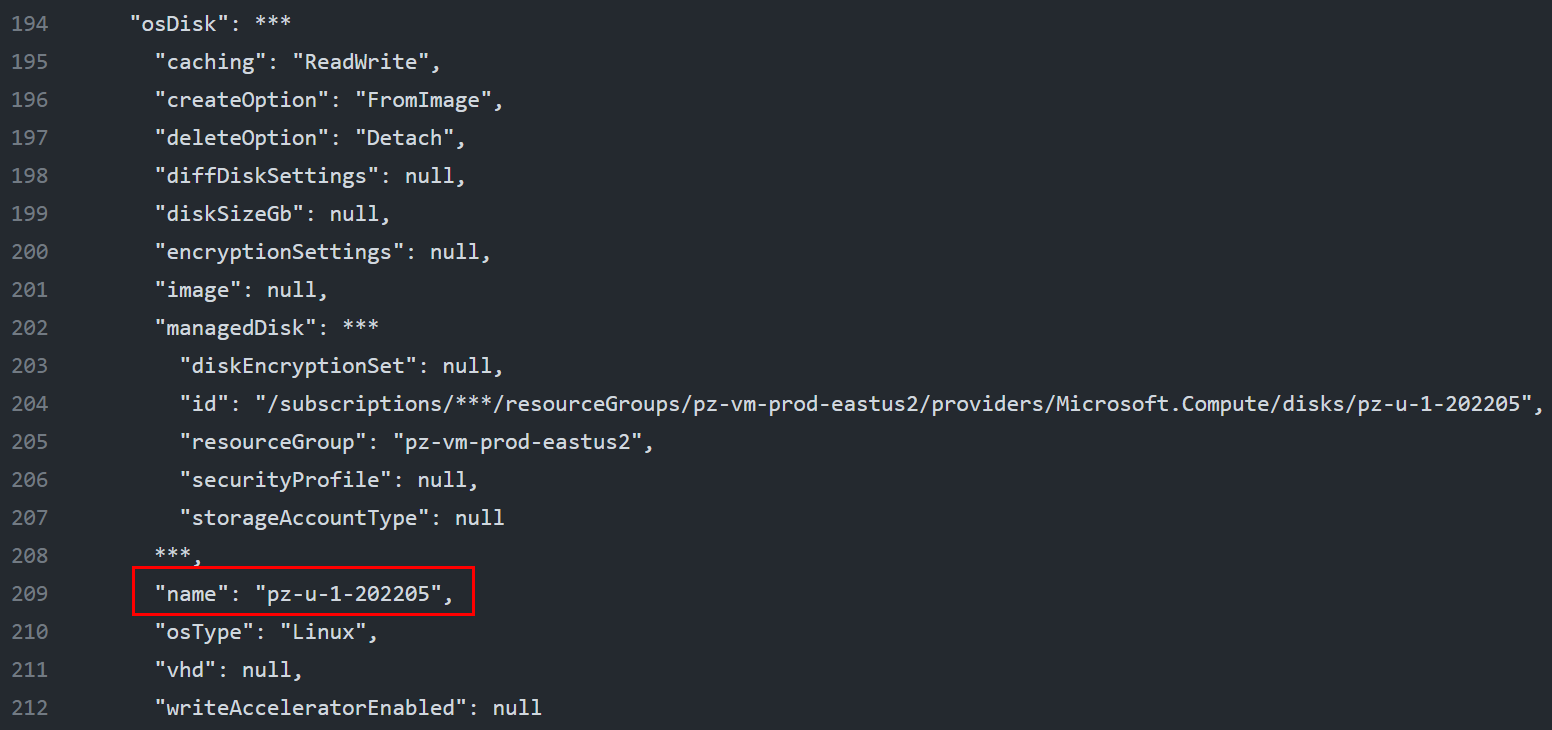
After the GitHub Actions run completes, we can refresh the VM properties and indeed, its OS disk is now the new pz-u-1-202205!

This shows that we can use this implementation both for at-scale, automated recurring OS disk creation and swap across many VMs, as well as for one VM or a few VMs at a time by just manually updating the OsDiskName tag value and running the GitHub Actions workflow.
The GitHub Actions workflows and scripts work either way - this was the goal of decoupling new OS disk creation from swapping new OS disks onto VMs, which I discussed above.
This is also a great way to maintain the principle of least privilege at scale. You can give an app or ops team Contributor RBAC role in the Resource Group where their VMs are deployed, so they can manually update OsDiskName tag values, and you can give them rights to run the corresponding GitHub Actions workflow.
That would be all the access they need to just swap OS disks around; no need to constantly open support tickets to ask someone else to do this, and no need to give them write access to a GitHub repo (e.g. to update some secret or file there with hard-coded values for OS disk names) or other configuration store.
Wrapping up
The GitHub Repo plzm/azure-vm-disk-swap contains the entire end-to-end implementation. You can fork and adjust it to your needs. Pull Requests are welcome!
The approach above accomplishes goals including least privilege including by using transient control plane access in highly restrictive environments; using resource tags for process guidance instead of updating a list or config store, or the GitHub repo, for each VM refresh; and replacing a high-risk, brute-force refresh approach with a low-downtime, high-resiliency approach.
Happy refreshing!